


Leader-based replication requires all writes to go through a single node, but read only queries can go to any replica. For workloads that consist of mostly reads and only a small percentage of writes (a common pattern on the web), there is an attrac‐ tive option: create many followers, and distribute the read requests across those followers. This removes load from the leader and allows read requests to be served by nearby replicas.
Unfortunately, if an application reads from an asynchronous follower, it may see outdated information if the follower has fallen behind. This leads to apparent inconsistencies in the database: if you run the same query on the leader and a follower at the same time, you may get different results, because not all writes have been reflected in the follower. This inconsistency is just a temporary state if you stop writing to the database and wait a while, the followers will eventually catch up and become consistent with the leader. For that reason, this effect is known as eventual consistency.
When the lag is so large, the inconsistencies it introduces are not just a theoretical issue but a real problem for applications. In this section we will highlight three examples of problems that are likely to occur when there is replication lag.
1. Reading your own writes
Many applications let the user submit some data and then view what they have submitted. This might be a record in a customer database, or a comment on a discussion thread, or something else of that sort. When new data is submitted, it must be sent to the leader, but when the user views the data, it can be read from a follower. With asynchronous replication, there is a problem, as illustrated in below figure: if the user views the data shortly after making a write, the new data may not yet have reached the replica. To the user, it looks as though the data they submitted was lost, so they will be understandably unhappy.
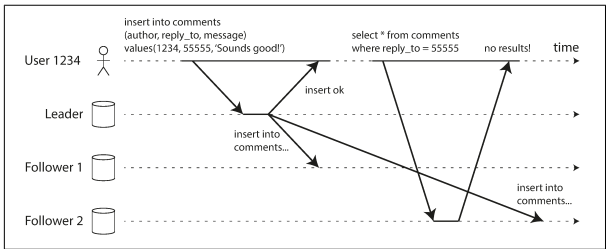
In this situation, we need read-after-write consistency, also known as read-your-writes consistency. This is a guarantee that if the user reloads the page, they will always see any updates they submitted themselves.
How can we implement read-after-write consistency in a system with leader-based replication? There are various possible techniques. To mention a few:
When reading something that the user may have modified, read it from the leader; otherwise, read it from a follower. This requires that you have some way of knowing whether something might have been modified, without actually querying it. For example, user profile information on a social network is nor‐ mally only editable by the owner of the profile, not by anybody else. Thus, a simple rule is: always read the user’s own profile from the leader, and any other users’ profiles from a follower
The client can remember the timestamp of its most recent write — then the system can ensure that the replica serving any reads for that user reflects updates at least until that timestamp. If a replica is not sufficiently up to date, either the read can be handled by another replica or the query can wait until the replica has caught up. The timestamp could be a logical timestamp (something that indicates the ordering of writes, such as the log sequence number) or the actual system clock.
2. Monotonic reads
Our second example of an anomaly that can occur when reading from asynchronous followers is that a user can see things moving backward in time.
This can happen if a user makes several reads from different replicas. For example, below figure shows user 2345 making the same query twice, first to a follower with little lag, then to a follower with greater lag. (This scenario is quite likely if the user refreshes a web page, and each request is routed to a random server.) The first query returns a comment that was recently added by user 1234, but the second query doesn’t return anything because the lagging follower has not yet picked up that write. In effect, the second query is observing the system at an earlier point in time than the first query. This wouldn’t be so bad if the first query hadn’t returned anything, because user 2345 probably wouldn’t know that user 1234 had recently added a com‐
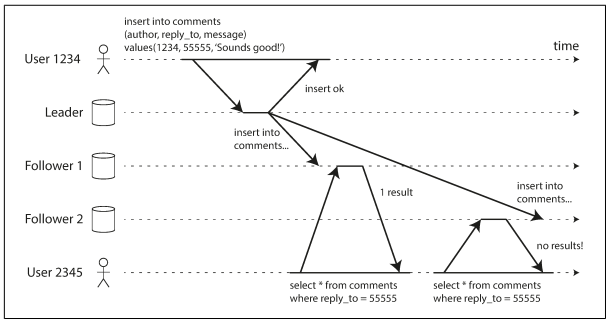
Monotonic reads is a guarantee that this kind of anomaly does not happen. It’s a lesser guarantee than strong consistency, but a stronger guarantee than eventual consistency. When you read data, you may see an old value; monotonic reads only means that if one user makes several reads in sequence, they will not see time go backward — i.e., they will not read older data after having previously read newer data.
3. Consistent Prefix reads
Consider the following dialogues:
Mr. Poons: How far into the future can you see, Mrs. Cake?
Mrs. Cake: About ten seconds usually, Mr. Poons.
Now, imagine a third person is listening to this conversation through followers. The things said by Mrs. Cake go through a follower with little lag, but the things said by Mr. Poons have a longer replication lag. This observer would hear the following:
Mrs. Cake: About ten seconds usually Mr. Poons.
Mr. Poons: How far into the future can you see, Mrs. Cake?
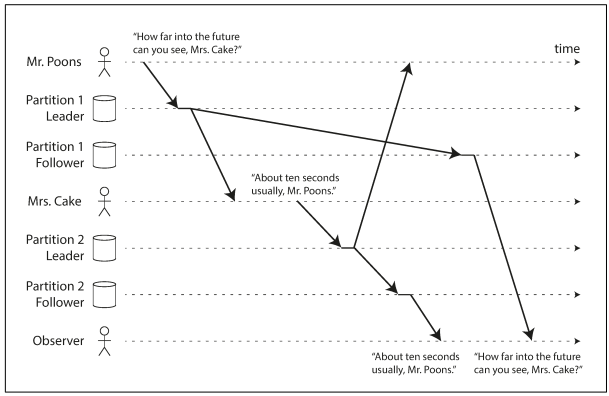
Preventing this kind of anomaly requires another type of guarantee: consistent prefix reads. This guarantee says that if a sequence of writes happens in a certain order, then anyone reading those writes will see them appear in the same order.
One solution is to make sure that any writes that are causally related to each other are written to the same partition but in some applications that cannot be done efficiently. Some algorithms explicitly keeptrack of causal dependencies, a topic that we will return to in “The “happens-before” relationship and concurrency”.
Reference : Kleppmann, Martin — Designing data-intensive applications